

{kind=link}
A few months ago, I wrote about the security of AI models, fine-tuning techniques, and the use of Retrieval-Augmented Generation (RAG) in a Cisco Security Blog post. In this blog post, I will continue the discussion on the critical importance of learning how to secure AI systems, with a special focus on current LLM implementations and the “LLM stack.”
I also recently published two books. The first book is titled “The AI Revolution in Networking, Cybersecurity, and Emerging Technologies” where my co-authors and I cover the way AI is already revolutionizing networking, cybersecurity, and emerging technologies. The second book, “Beyond the Algorithm: AI, Security, Privacy, and Ethics,” co-authored with Dr. Petar Radanliev of Oxford University, presents an in-depth exploration of critical subjects including red teaming AI models, monitoring AI deployments, AI supply chain security, and the application of privacy-enhancing methodologies such as federated learning and homomorphic encryption. Additionally, it discusses strategies for identifying and mitigating bias within AI systems.
For now, let’s explore some of the key factors in securing AI implementations and the LLM Stack.
What is the LLM Stack?
The “LLM stack” generally refers to a stack of technologies or components centered around Large Language Models (LLMs). This “stack” can include a wide range of technologies and methodologies aimed at leveraging the capabilities of LLMs (e.g., vector databases, embedding models, APIs, plugins, orchestration libraries like LangChain, guardrail tools, etc.).
Many organizations are trying to implement Retrieval-Augmented Generation (RAG) nowadays. This is because RAG significantly enhances the accuracy of LLMs by combining the generative capabilities of these models with the retrieval of relevant information from a database or knowledge base. I introduced RAG in this article, but in short, RAG works by first querying a database with a question or prompt to retrieve relevant information. This information is then fed into an LLM, which generates a response based on both the input prompt and the retrieved documents. The result is a more accurate, informed, and contextually relevant output than what could be achieved by the LLM alone.
Let’s go over the typical “LLM stack” components that make RAG and other applications work. The following figure illustrates the LLM stack.
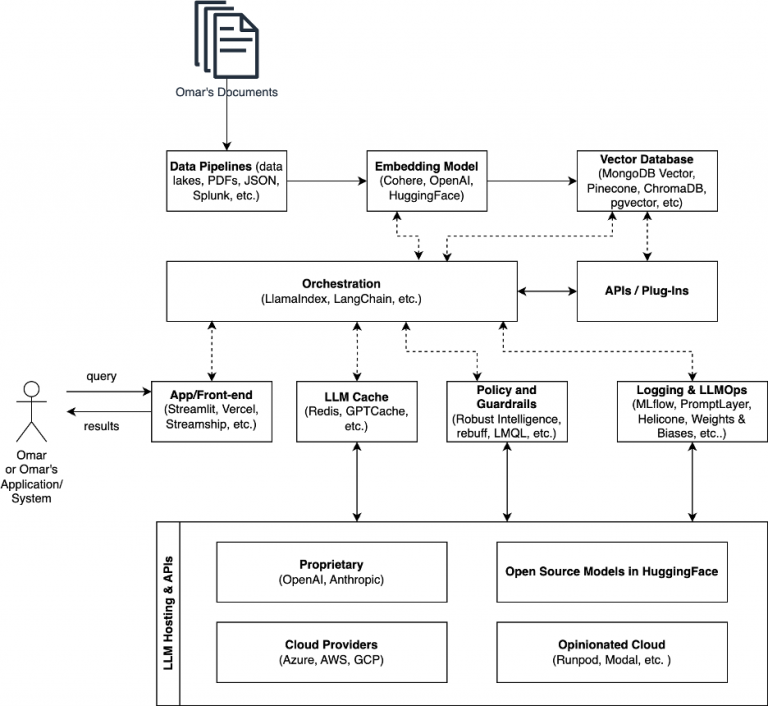
Vectorizing Data and Security
Vectorizing data and creating embeddings are crucial steps in preparing your dataset for effective use with RAG and underlying tools. Vector embeddings, also known as vectorization, involve transforming words and different types of data into numerical values, where each piece of data is depicted as a vector within a high-dimensional space. OpenAI offers different embedding models that can be used via their API. You can also use open source embedding models from Hugging Face. The following is an example of how the text “Example from Omar for this blog” was converted into “numbers” (embeddings) using the text-embedding-3-small model from OpenAI.
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
0.051343333,
0.004879803,
-0.06099363,
-0.0071908776,
0.020674748,
-0.00012919278,
0.014209986,
0.0034705158,
-0.005566879,
0.02899774,
0.03065297,
-0.034541197,
<output omitted for brevity>
]
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 6,
"total_tokens": 6
}
}
The first step (even before you start creating embeddings) is data collection and ingestion. Gather and ingest the raw data from different sources (e.g., databases, PDFs, JSON, log files and other information from Splunk, etc.) into a centralized data storage system called a vector database.
Note: Depending on the type of data you will need to clean and normalize the data to remove noise, such as irrelevant information and duplicates.
Ensuring the security of the embedding creation process involves a multi-faceted approach that spans from the selection of embedding models to the handling and storage of the generated embeddings. Let’s start discussing some security considerations in the embedding creation process.
Use well-known, commercial or open-source embedding models that have been thoroughly vetted by the community. Opt for models that are widely used and have a strong community support. Like any software, embedding models and their dependencies can have vulnerabilities that are discovered over time. Some embedding models could be manipulated by threat actors. This is why supply chain security is so important.
You should also validate and sanitize input data. The data used to create embeddings may contain sensitive or personal information that needs to be protected to comply with data protection regulations (e.g., GDPR, CCPA). Apply data anonymization or pseudonymization techniques where possible. Ensure that data processing is performed in a secure environment, using encryption for data at rest and in transit.
Unauthorized access to embedding models and the data they process can lead to data exposure and other security issues. Use strong authentication and access control mechanisms to restrict access to embedding models and data.
Indexing and Storage of Embeddings
Once the data is vectorized, the next step is to store these vectors in a searchable database or a vector database such as ChromaDB, pgvector, MongoDB Atlas, FAISS (Facebook AI Similarity Search), or Pinecone. These systems allow for efficient retrieval of similar vectors.
Did you know that some vector databases do not support encryption? Make sure that the solution you use supports encryption.
Orchestration Libraries and Frameworks like LangChain
In the diagram I used earlier, you can see a reference to libraries like LangChain and LlamaIndex. LangChain is a framework for developing applications powered by LLMs. It enables context-aware and reasoning applications, providing libraries, templates, and a developer platform for building, testing, and deploying applications. LangChain consists of several parts, including libraries, templates, LangServe for deploying chains as a REST API, and LangSmith for debugging and monitoring chains. It also offers a LangChain Expression Language (LCEL) for composing chains and provides standard interfaces and integrations for modules like model I/O, retrieval, and AI agents. I wrote an article about numerous LangChain resources and related tools that are also available at one of my GitHub repositories.
Many organizations use LangChain supports many use cases, such as personal assistants, question answering, chatbots, querying tabular data, and more. It also provides example code for building applications with an emphasis on more applied and end-to-end examples.
Langchain can interact with external APIs to fetch or send data in real-time to and from other applications. This capability allows LLMs to access up-to-date information, perform actions like booking appointments, or retrieve specific data from web services. The framework can dynamically construct API requests based on the context of a conversation or query, thereby extending the functionality of LLMs beyond static knowledge bases. When integrating with external APIs, it’s crucial to use secure authentication methods and encrypt data in transit using protocols like HTTPS. API keys and tokens should be stored securely and never hard-coded into the application code.
AI Front-end Applications
AI front-end applications refer to the user-facing part of AI systems where interaction between the machine and humans takes place. These applications leverage AI technologies to provide intelligent, responsive, and personalized experiences to users. The front end for chatbots, virtual assistants, personalized recommendation systems, and many other AI-driven applications can be easily created with libraries like Streamlit, Vercel, Streamship, and others.
The implementation of traditional web application security practices is essential to protect against a wide range of vulnerabilities, such as broken access control, cryptographic failures, injection vulnerabilities like cross-site scripting (XSS), server-side request forgery (SSRF), and many other vulnerabilities.
LLM Caching
LLM caching is a technique used to improve the efficiency and performance of LLM interactions. You can use implementations like SQLite Cache, Redis, and GPTCache. LangChain provides examples of how these caching methods could be leveraged.
The basic idea behind LLM caching is to store previously computed results of the model’s outputs so that if the same or similar inputs are encountered again, the model can quickly retrieve the stored output instead of recomputing it from scratch. This can significantly reduce the computational overhead, making the model more responsive and cost-effective, especially for frequently repeated queries or common patterns of interaction.
Caching strategies must be carefully designed to ensure they do not compromise the model’s ability to generate relevant and updated responses, especially in scenarios where the input context or the external world knowledge changes over time. Moreover, effective cache invalidation strategies are crucial to prevent outdated or irrelevant information from being served, which can be challenging given the dynamic nature of knowledge and language.
LLM Monitoring and Policy Enforcement Tools
Monitoring is one of the most important elements of LLM stack security. There are many open source and commercial LLM monitoring tools such as MLFlow. There are also several tools that can help protect against prompt injection attacks, such as Rebuff. Many of these work in isolation. Cisco recently announced Motific.ai.
Motific enhances your ability to implement both predefined and tailored controls over Personally Identifiable Information (PII), toxicity, hallucination, topics, token limits, prompt injection, and data poisoning. It provides comprehensive visibility into operational metrics, policy flags, and audit trails, ensuring that you have a clear oversight of your system’s performance and security. Additionally, by analyzing user prompts, Motific enables you to grasp user intents more accurately, optimizing the utilization of foundation models for improved outcomes.
Cisco also provides an LLM security protection suite inside Panoptica. Panoptica is Cisco’s cloud application security solution for code to cloud. It provides seamless scalability across clusters and multi-cloud environments.
AI Bill of Materials and Supply Chain Security
The need for transparency, and traceability in AI development has never been more crucial. Supply chain security is top-of-mind for many individuals in the industry. This is why AI Bill of Materials (AI BOMs) are so important. But what exactly are AI BOMs, and why are they so important? How do Software Bills of Materials (SBOMs) differ from AI Bills of Materials (AI BOMs)? SBOMs serve a crucial role in the software development industry by providing a detailed inventory of all components within a software application. This documentation is essential for understanding the software’s composition, including its libraries, packages, and any third-party code. On the other hand, AI BOMs cater specifically to artificial intelligence implementations. They offer comprehensive documentation of an AI system’s many elements, including model specifications, model architecture, intended applications, training datasets, and additional pertinent information. This distinction highlights the specialized nature of AI BOMs in addressing the unique complexities and requirements of AI systems, compared to the broader scope of SBOMs in software documentation.
I published a paper with Oxford University, titled “Toward Trustworthy AI: An Analysis of Artificial Intelligence (AI) Bill of Materials (AI BOMs)”, that explains the concept of AI BOMs. Dr. Allan Friedman (CISA), Daniel Bardenstein, and I presented in a webinar describing the role of AI BOMs. Since then, the Linux Foundation SPDX and OWASP CycloneDX have started working on AI BOMs (otherwise known as AI profile SBOMs).
Securing the LLM stack is essential not only for protecting data and preserving user trust but also for ensuring the operational integrity, reliability, and ethical use of these powerful AI models. As LLMs become increasingly integrated into various aspects of society and industry, their security becomes paramount to prevent potential negative impacts on individuals, organizations, and society at large.
Sign up for Cisco U. | Join the Cisco Learning Network.
Follow Cisco Learning & Certifications
Twitter | Facebook | LinkedIn | Instagram | YouTube
Use #CiscoU and #CiscoCert to join the conversation.
Share: